IPFS和博客
似乎这是两码事?
IPFS
IPFS 全称 (InterPlanetary File System),中文名可叫星际文件系统。
这略带一丝中二的名字确实透露了这项目的愿景,设想一下,要是人类真的在太阳系殖民成功了,各个殖民地要如何通信?就算是火星和地球光也要走三分钟,最低六分钟的延迟,谁受得了啊?
但观测一下就可以发现,网络中的很多数据是可以复用的。比如,火星上的 A 访问了地球的今日新闻,火星上的 B 想访问地球的今日新闻网站,还要去跟地球通信吗?他只要跟 A 获取数据就可以了。
这就是 IPFS 的基本思想了,一个点对点的分布式文件系统。
能做啥
作为一个点对点的分布式文件系统,基本功能就是存储文件了,图片、视频、静态网页、文件夹皆可。
文件上传后,再经过算(mo)法后,文件会被标上一个类似于 Qmd3oSMoEb3npqXdjwek7RPfvteMckrBFBRHU1ECZDtAEC 这种形式的 CID ,这个 CID 可以唯一标识一个文件,其他人将这个 CID 告诉 IPFS 网络,就可以在全世界的 IPFS 网络中进行获取了。
网关
但遗憾的是 IPFS 不能兼容现在主流的 HTTP 网络,如果没有专门的客户端又想要使用 IPFS 网络,要借助一个网关才可以。
好比如世界上有一群人发明了一种新语言,这种语言甚至需要借助一个新器官才能沟通,很明显其他人是完全无法同使用新语言的人交流的。新语言使用者为了增大影响力,决定派出几名翻译,让双方能够沟通。
可通过公共网关检查站获知常见公共网关。
国内访问优秀的网关为:
w3s.link cloudflare-ipfs.com (Cloudflare 我的超人!)
ipfs.fleek.co
在网关后面加上 /ipfs/[cid] 即可通过 http 的形式获取文件了。
试试看↓:
/ipfs/Qmd3oSMoEb3npqXdjwek7RPfvteMckrBFBRHU1ECZDtAEC
IPNS
cid 形式有个问题就是他是根据文件内容进行计算的,文件内容哪怕改动一个字,生成的 cid 也会完全不同……如果要在 IPFS 网络部署一个网站的话,管理员每次更新网站,就得把新 cid 重新告知出去吗?
显然太折腾了……但可以利用现有的 DNS ,将 cid 绑定到 DNS 上,这样管理方仅需更新 DNS 即可。这种方式被成为 IPNS ( InterPlanetary Name System) 。
通过这种方式,可以将一个静态网站托管到 IPFS 网络上面,生命力大大增强。
一般网关也支持 IPNS 形式访问,在网关后面加上 /ipns/[域名] 即可。
试试看↓:
/ipns/zh.wikipedia-on-ipfs.org (一个静态的维基百科存档)
/ipns/blog.southfox.me (当然!)
IPFS 图床
那么托管文件,最容易想到的就是图片了,本博客的图片也在几个月前迁移到了 IPFS 网络上。
如果真想将图片放到 IPFS 上,那么该考虑以下事情:
优点:
抗☐☐,即使一个网关炸掉了,也可以切换另一个网关。
轻松切换, 文件
cid是不变的,VS Code全文替换就可以很轻松切到另一个网关,不像一般图床,其连接是随机的,其迁移成本会变得非常大。
缺点:
- 慢……速度一般来说只能说凑合,除非将设置一个靠近用户的位置放置网关,同时文件刚好就在这网关上……
web3.storage
可使用 GitHub 注册,这网站提供 1T 的存储空间。
fleek.co
同样可使用 GitHub 注册,可提供存储空间不明。
但是重点是!他提供网站托管!
Pinata
1G 免费空间……但似乎是 IPFS 客户端能直接连接过去进行备份?总之不推荐(因为空间太小了)。
公共网关
以上的网站是要自己手动上传至他们的网页,并没有很好的支持 HTTP API ,所以喜欢用 PicGo 传图并直接获取 MarkDown 连接的懒人可能要寻找能够直接传图的公共网关了。
PicGo
在插件市场搜索 web-uploader-custom-url-prefix 并进行安装,配置成如下:
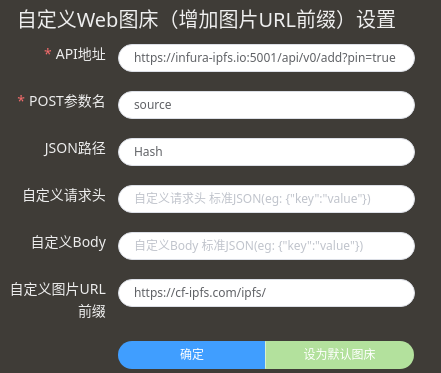
其中 infura-ipfs.io 可以是任意支持 HTTP API 形式上传的网关。
自定义图片前缀可以是任意访问速度快的网关。
Python
想用 Python 折腾?好主意,所以快去折腾吧!
快捷命令
没用过苹果设备,不清楚。
不过一般参照之前经验改改应该不难……?
Pin 与失效
前面的 PicGo 上传图片时带有个 pin=true 参数,这个参数就是告诉网关,这个文件很重要,请不要当成缓存清除。
因为 IPFS 的设置是,其他节点获取了一个文件后,会放在缓存里,如果服务器的缓存超过了阈值(默认 10G),就会清理掉……
如果上传文件的服务器下线了,那么还是有可能从缓存了这文件的服务器获取文件的。但万一时间太过久远,久到主服务器不存在,其他服务器缓存早已清理,那么这个文件就如同 BiTorrent 下载中的死种一样,再也不能获取了……
而另一面讲,如果文件很热门,比如明星艳照,那么这个文件将会持久存在,删除不能……所以,**不要向 IPFS 上传个人隐私相关文件!**一旦传播开来,那就没有后悔药了……
备份
所以为了数据安全考虑,放置在 IPFS 上的图片也要做好备份……
似乎可以写个脚本,自动分析文件下的 cid ,然后自动爬取备份到本地。
<del>以后再摸吧。</del>
3-13 更新:
其实当天就摸了……只是我憋着不放呢。(
import sys
import os
import requests
import json
import re
import random
def backupImg():
path = os.getcwd()
for root, dirs, files in os.walk(path + '/source'): #根据实际情况定
for name in files :
filelist.append(os.path.join(root, name))
nowImgList = []
for filename in filelist:
if filename.endswith('.md'):
if "_posts/" in filename:
post = filename.split("_posts/")[-1]
with open(filename, "r", encoding='utf-8') as f:
mdText = f.read()
result = re.findall('!\[(.*?)\]\((.*?)\)', mdText)
for i in range(len(result)):
img_quote = result[i][0]
img_url = result[i][1]
nowImgList.append(img_url)
downLoadList = list(set(nowImgList).difference((set(imgJson["img"]))))
if downLoadList != '':
nowImgJson = {}
nowImgJson["img"] = nowImgList
with open('./imgList.json', 'w', encoding='utf-8') as f:
json.dump(nowImgJson, f)
downloadImg(downLoadList)
def downloadImg(imgList):
for img_url in imgList:
if img_url == '': #判空
continue
# img name spell
urlname = img_url.split(u"/")
img_name = str(urlname[-1])
# download img
ipfs_gateWay = ['https://ipfs.io/ipfs/', 'https://ipfs.fleek.co/ipfs/']
if 'ipfs' in img_url:
img_url = random.choice(ipfs_gateWay) + img_name
response = requests.get(img_url) #根据自己图床链接进行选择
print('Download ' + img_url + '✔️')
# write to file
f_img = open('./' + img_name, 'wb')
f_img.write(response.content)
f_img.close()
if __name__ == '__main__':
filelist = []
if os.path.exists('./imgList.json'):
imgJson = []
with open('./imgList.json', 'r', encoding='utf-8') as f:
imgJson = json.load(f)
else:
imgJson = {}
imgJson["img"] = []
backupImg()简单来说,就是用扫描 source 目录下的的 .md 文件,并用正则扫描 ![]() 这种形式的图片语法并存起来。
然后进行图片抓取,其中 if 'ipfs' in img_url: 这里是判断链接是否是 ipfs 的图床链接,要是你的图片链接只来源一个图床(例如 sm.ms 可以写 if 'loli.net' in img_url:),请自行替换,要是图床来源杂乱就……不进行判断抓取下来自己手动选择吧。
然后结束后会生成一个 imgList.json 文件,里面是已经抓取的图片,以后要是再进行抓取的话就通过这文件和新扫描的文件列表做集合的求差处理(downLoadList = list(set(nowImgList).difference((set(imgJson["img"]))))),以来判断要新抓取那些文件……
<del>总之写的非常初学者……应该都是比较好理解的吧(</del>
很多都是为了 GitHub Actions 准备的,不知道是什么的话可以看这。
IPFS 博客
如果你有一个静态博客,为何不考虑放置在 IPFS 网络上呢?
首先要更改的就是博客的连接……要前往博客模板把其里面的所有连接都改成相对连接的形式,否则托管时会根本加载不了 css 或者 js 文件。
接着前往 fleek 并注册,然后在托管一栏中选择你放置静态网页的仓库(或分支),就能简单的部署到 IPFS 网络上了,要是想启用 IPNS ,也可以在 SETTINGS -> Domain Management -> Add Custom Domain 增加一个博客域名,然后在新增域名的更多选项里选择 Dns Link ,会自动弹出个窗口绑定域名。把这个 CNAME 选项绑定到你的域名管理商即可。(Cloudflare 我默认关了代理,要是绑定迟迟不能生效的话可以试着关掉 Cloudflare 代理试试)
实际使用
客户端
不一定需要个网关,实际自己直接用用也是不错的,就是使用时会不停的交换数据,对电量和流量的消耗也很大……如果所在网络对 P2P 协议限制比较严格那可就要小心了……
服务端
如果你手头上有闲置的服务器,为什么不尝试部署一个 IPFS 服务呢?
将文件放一份备份在自己的服务器上,或是搭建一个自用网关,也能有效提升使用体验(当然要服务器性能足够)。
文件币
哦……所以还是谈论到这个话题了……
filecoin ,是一个建立在 IPFS 上的加密货币项目(大概)?
只要你抵押出相当容量的硬盘,就能进行挖矿了……这似乎也是去年硬盘涨价风潮原因之一?<del>(那更该用了,这是拿大众的钱买硬盘啊)</del>
但现在这币似乎状态不好的样子,价格跌倒了顶值的十分之一。虽然我对加密货币不感冒,但我还是想 fil 涨起来的,毕竟币涨了也是能吸引更多人提供存储空间的,经营托管服务的服务商也能通过 fil 进行回本。
但是不考虑加密货币也罢, IPFS 做为一个开源项目,如果其足够好,也能自己证明自己,IPFS 能取代 HTTP 成为下一代网络标准吗?天知道。
